
| |
| Term | Description | Sample Tool | Corresponding Squeak Tool |
| Source Code Control (Development Process) | Managing source code that is part of one or more projects. May include managing versions, history, releases, etc. | CVS client (user interface), server (manager) and repository (backend store) | Monticello Browser (user interface), (manager and backend store) |
| Package (Development Process) | A unit of code (multiple classes) that are managed as one "unit" in for development or release. Monticello using the word "Package" for source code control is perhaps confusing, as "Package" often defines collection of installable binary that provides certain functionality (Linux RPM package). But anyway, the term "Package" or "Monticello Package" will be used to describe a unit of managed code. | .rpm file, .deb file | .mcz file |
| Version Management (Development Process) | Ability to mark certain state of code as a "version" | CVS tag (e.g. 2.0.17) | Monticello Version, for example, MorphicWrappers-mz.2017 |
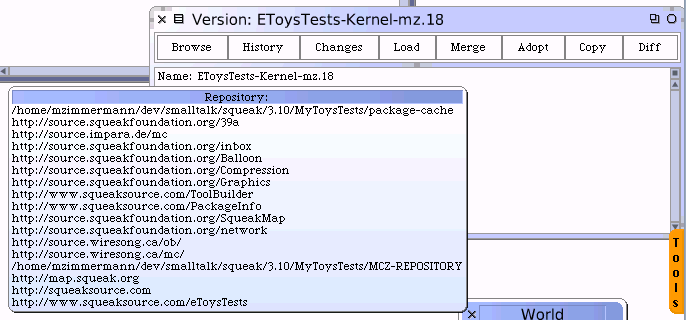
| Package Repository (Distribution Process) | Place which holds packaged software, available for users to be installed on their system. | In Linux, http or ftp repository of .RPM, .DEB packages. For example, SuSE Linux repository of KDE core packages is on http://download.opensuse.org/repositories/KDE:/KDE4:/STABLE:/Desktop/openSUSE_11.1/. Repository can be accessed by web browser, but to install packages on user's system a Package Installer such as Yast or Yum is typically used. | SqueakMap - all packages repository is located on http://map.squeak.org/packagesbyname. As in the Linux equivalent, SquekMap Repository can be accessed by web browser, but to install packages on user's system a Package Installer such as SqueakMap Package Loader is typically used. |
== continue cleanup here vvvv ===
| Package Installer | Allows to install packaged software from Package Repository (see above) | Yast, Yum, Apt-get (installs into linux, resolves dependencies) | SqueakMap Package Loader (installs into your image, NOT the OS). Note that in Squeak's SqueakMap Package Loader, resolving dependencies is weak (almost nonexistent, ususally defined as instructions "install A,B,C before D)" |
| ToDo How to explain difference between Monticello Repository and Monticello Repository on SqueakSource? Source Code Repository | Place which holds source code, shareable by developers | CVS Repository | TODO Monticello Repository (Backend) Monticello Browser (Client, this is what developer uses) |
==================== =================================
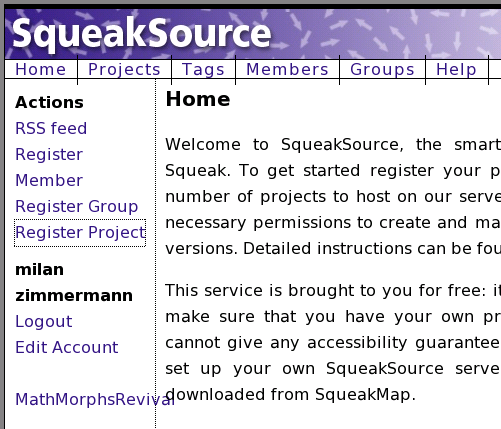 as in the screenshot.
as in the screenshot.
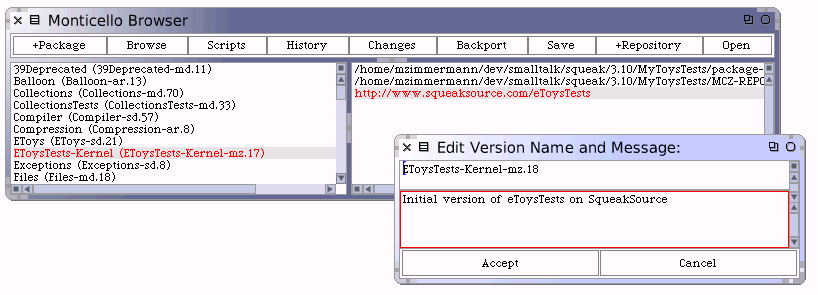
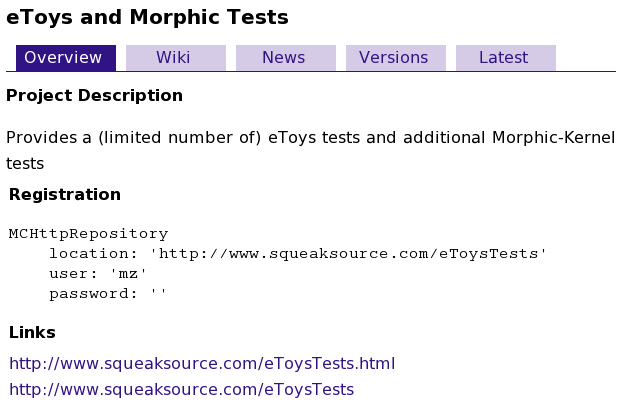 Below, when adding Monticello code Package to the Project we created, we will be pasting the Registration string into Monticello Browser.
Below, when adding Monticello code Package to the Project we created, we will be pasting the Registration string into Monticello Browser.
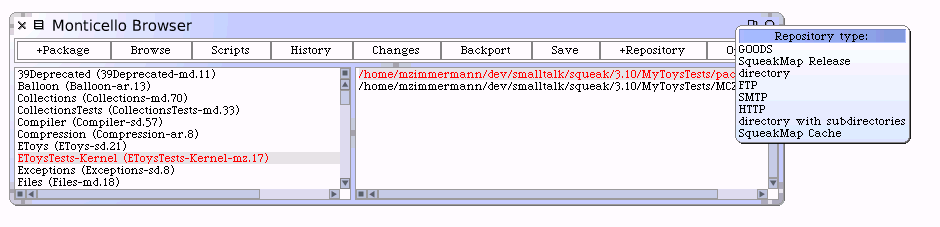 By the way, the if you want to create a "local repository" on your system, as opposed a repository on SqueakMap, select "directory" - that is the only difference!. Your source code control would then be on your local system directory.
By the way, the if you want to create a "local repository" on your system, as opposed a repository on SqueakMap, select "directory" - that is the only difference!. Your source code control would then be on your local system directory.
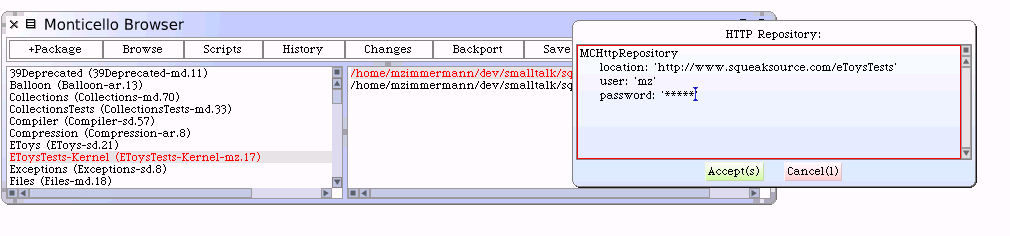 Here is where we can simply paste the Registration item, and add your password and click "Accept".
Here is where we can simply paste the Registration item, and add your password and click "Accept".
============== MCHttpRepository location: 'http://www.squeaksource.com/MathMorphsRevival' user: 'mz' password: 'HIDDEN' ==============